
What is Generative AI? A Comprehensive Guide for Everyone
Demystifying generative AI for beginners and experts alike.


At first glance, generative AI looks like pure magic. But once you start to peel back the layers behind this fascinating technology, you see it for what it is: a statistical process with both impressive results and critical limitations.
In its broadest sense, generative AI is a type of artificial intelligence that creates novel content based on patterns learned from existing data. Perhaps the most obvious example of generative AI is predictive search. Google trains a large language model (LLM) on billions of search queries made by users over the years, which then tries to predict the next word in your own search query.
But predictive search is old school, even primitive, compared to recent advancements in generative AI. Generative AI can now be used to write everything from new Seinfeld episodes to scholarly articles, synthesize images based on text prompts, and even produce songs in the likeness of famous artists.
Despite the hype, there is cause for concern. Chatbots powered by generative AI can produce inaccurate and toxic responses, deepfake videos of politicians and public figures can be used for spreading disinformation, and models of any kind can be used to reinforce existing human biases.
It’s clear that generative AI will impact labor, industry, government, and even what it means to be human. In order to coexist with generative AI, we need to understand how it works and the risks it poses. This article will explain what a machine learning model is, discuss the difference between discriminative and generative models, explore some real-world applications of generative models, and touch on their risks and limitations.
Machine learning models
Artificial intelligence is a broad term that describes a piece of technology that can perform tasks that mimic human intelligence, such as those requiring reasoning, problem-solving, decision-making, or language understanding.
Machine learning is a branch of AI in which “machines” (algorithms) “learn” patterns and associations from data in order to perform specific tasks. This is how it works:
- Define the task. The first thing we need to do is define the task that we want the model to perform. This could be classifying an incoming email as spam or not spam, predicting future revenue based on sales data, assigning customers to different groups based on their behavior, recommending new products for customers based on their purchasing history, or creating an image based on a given text prompt.
- Select the model. There are many different factors that influence which type of model we want to choose. The task we defined in the previous step, along with the nature and amount of available data, and how the model will be used in the real world (and by whom) all influence the type of model we want to use.
- Collect (and clean) the data. Next, we collect data that we want our model to learn from. We clean it up by deleting outliers and corrupted data and organize it in a tabular format.
- Optional: Split the data. When learning from data, we often set aside a chunk (usually 80%) to build our knowledge, which is known as the training data. We then use the remaining portion (typically 20%), which is called the validation data, to check how well we've learned. This process helps us see if our understanding of the training data holds up against new information.
- Train the model. Next, we take our empty model and tell it to learn as much as it can from the training data. This is called the training process because the model is being trained (i.e. it's learning, studying, and analyzing the relationships in the data). We can give a model a little guidance and nudge it in certain directions by choosing parameters for the model.
- Evaluate the model. Before releasing the model into the wild, we want to get an idea of how well it performs by seeing how it scores on certain metrics, like accuracy, precision, recall, and F1 score. If we have a validation set, we can ask the model to perform the chosen task on the validation set and see how accurate it is.
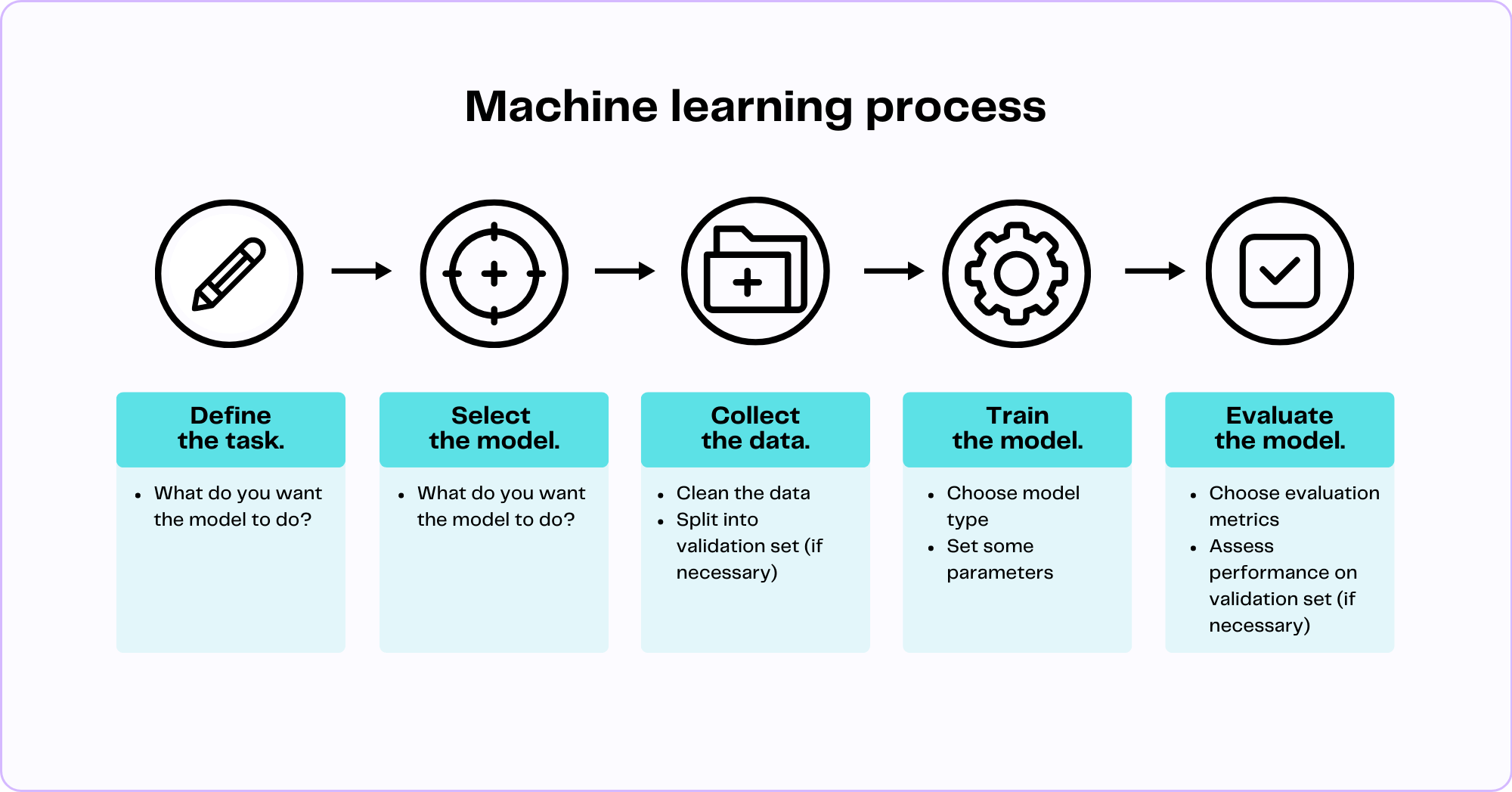
Machine learning is an intricate, iterative, and ever-evolving process. Most interest is centered on the model training step, but most time is actually spent on the data collection and cleaning step. Just as fossil fuels like oil and natural gas are sent from one location to the other through an intricate series of pipelines, data has its own set of pipelines as well. Once pipelines are up and running, they need constant monitoring and maintenance, but getting to that point takes a tremendous amount of work.
However, for the purpose of this article, we're going to focus on the machine learning models themselves. In order to effectively understand generative AI, we must understand the difference between generative and discriminative machine learning models.
Discriminative models vs. generative models
The job of a model is to use these associations and patterns learned from a dataset to predict outcomes on other data points. These predictions come in the form of probabilities between 0 and 1. And because probability is a measure of uncertainty, and there is always some degree of uncertainty present in real-world situations, predicted probabilities can never be equal to exact 0 or 1.
Machine learning models vary in the methods they generate predicted probabilities for data points. In the context of generative AI, it’s important to understand the distinctions between how discriminative models and generative models generate these predicted probabilities.
Discriminative models
Discriminative models learn to predict probabilities for data based on recognizing the differences between groups or categories based on examples they've seen before.
For instance, a logistic regression model can predict the probability of a binary outcome, such as the probability of a student passing a class based on features like attendance rate, hours spent studying, previous exam scores, and the pass/fail status of past students.
Consider the illustration below, where each point is visualized as an individual student from the previous year with its own attendance rate, study time, previous exam scores, and final pass/fail status. Given the individual features and final outcomes for each student, the model draws a decision boundary.
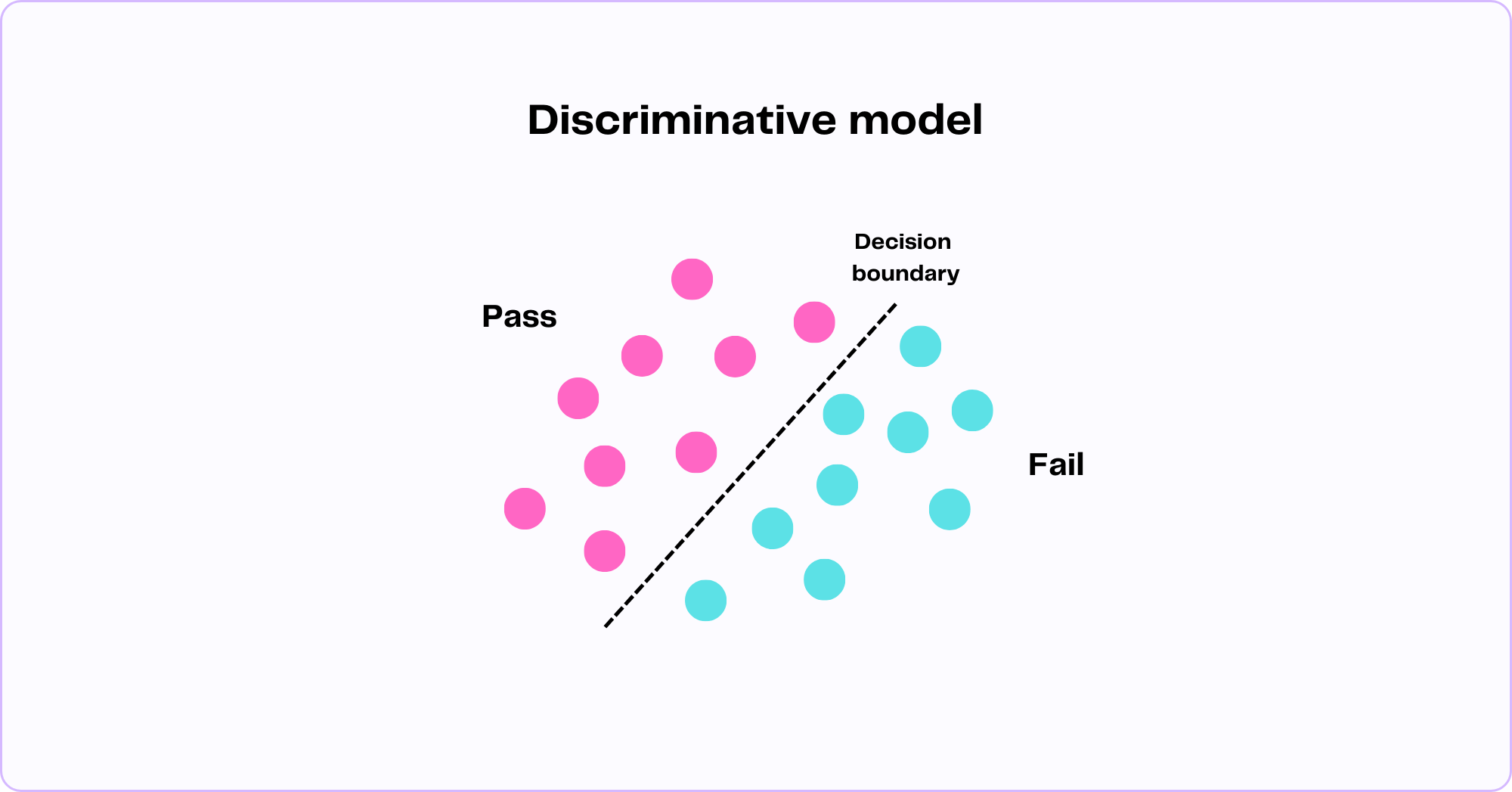
When presented with new students and their data, the model uses the decision boundary to predict whether or not they will pass the class, represented by a probability between 0 (fail) and 1 (pass). The further a data point is from the decision boundary, the more confident the model is in its prediction.
While discriminative models can be simple and effective for tasks such as classification and regression, they can only perform well if they have access to sufficient labeled outcome data (past students' pass/fail status). In real-world tasks, this can be a serious limitation. And this is where generative models step in.
Generative models
Generative models learn to predict probabilities for data based on learning the underlying structure of the input data alone.
Generative models are so insanely good at studying and learning from the training data that they don't need labeled outcome data, like in the example above. This means two things:
- Generative models can predict probabilities for data (like discriminative models, but just using a different method).
- Generative models can generate new data that looks very similar to data it's seen before (the training data).
Consider the task of figuring out whether an Amazon review for a product is generally positive or negative. In the illustration below, each point is visualized as an individual review, with its own style, tone, and unique combination of words and phrases. A generative model studies all these data points, capturing the patterns, structure, and variations in language for each review as well as their relationships to each other.
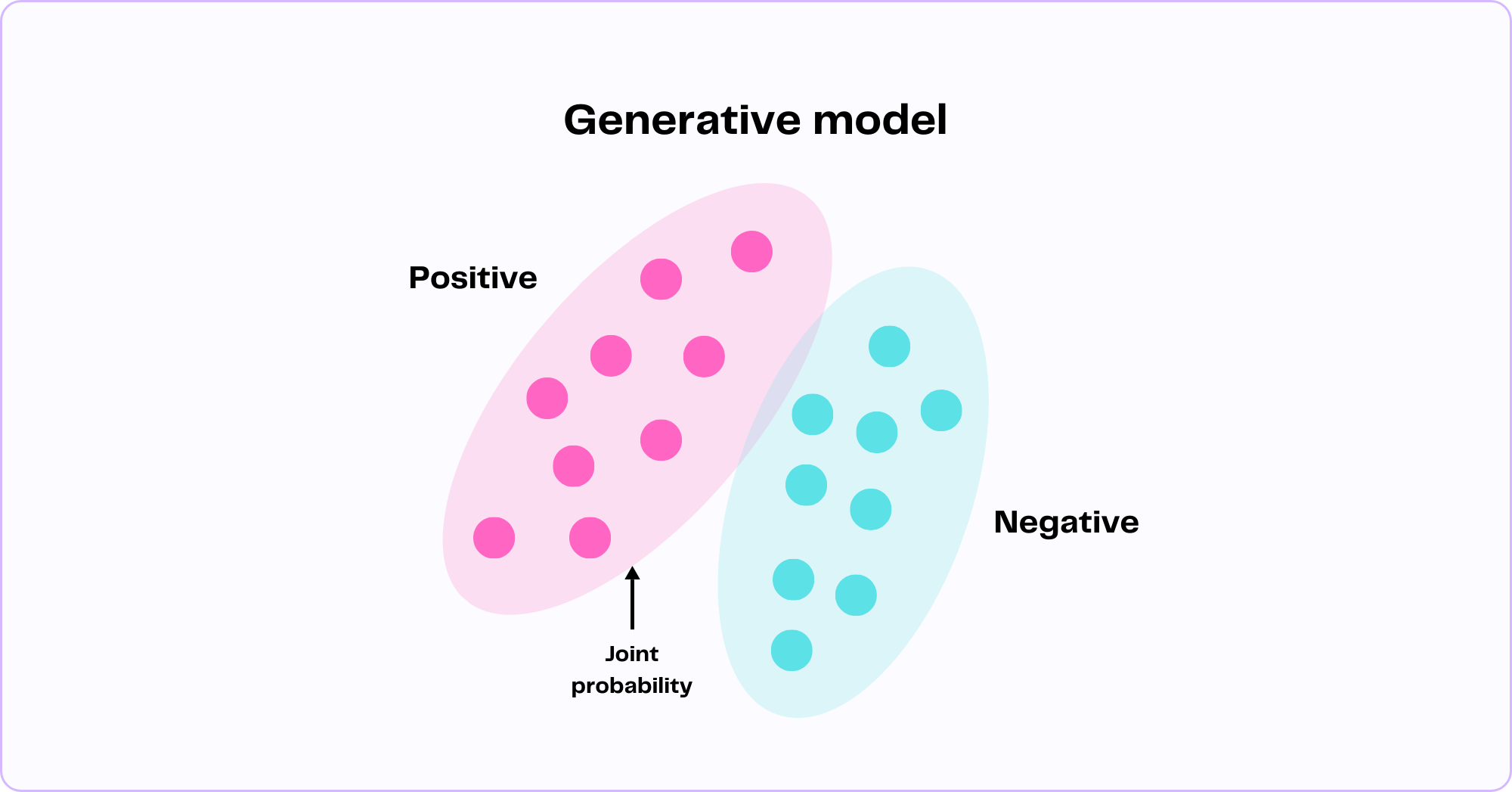
Given all of the words and patterns in all of the reviews, a generative model calculates the probability of those words and patterns occurring in a positive review versus a negative review. This probability is called the joint probability and is defined as the probability of a set of features occurring together in the data. For instance, the model may learn that words like "broken" and "disappointed" occur frequently together within negative reviews while words like "highly recommend" and "very satisfied" occur frequently together in positive reviews.
Ultimately, the model will apply all the knowledge it has learned from the training data to determine the likelihood of new, unseen reviews being classified as either positive or negative. What sets generative models apart from discriminative models is the fact that they can perform classification tasks as well as generate completely new data, when prompted. This means that our Amazon review model can classify existing reviews as well as write new reviews.
When working on a generative task, a model needs to be prompted. In this case, a model that has already been trained on reviews is fed a prompt of text and is asked to guess which words come next.
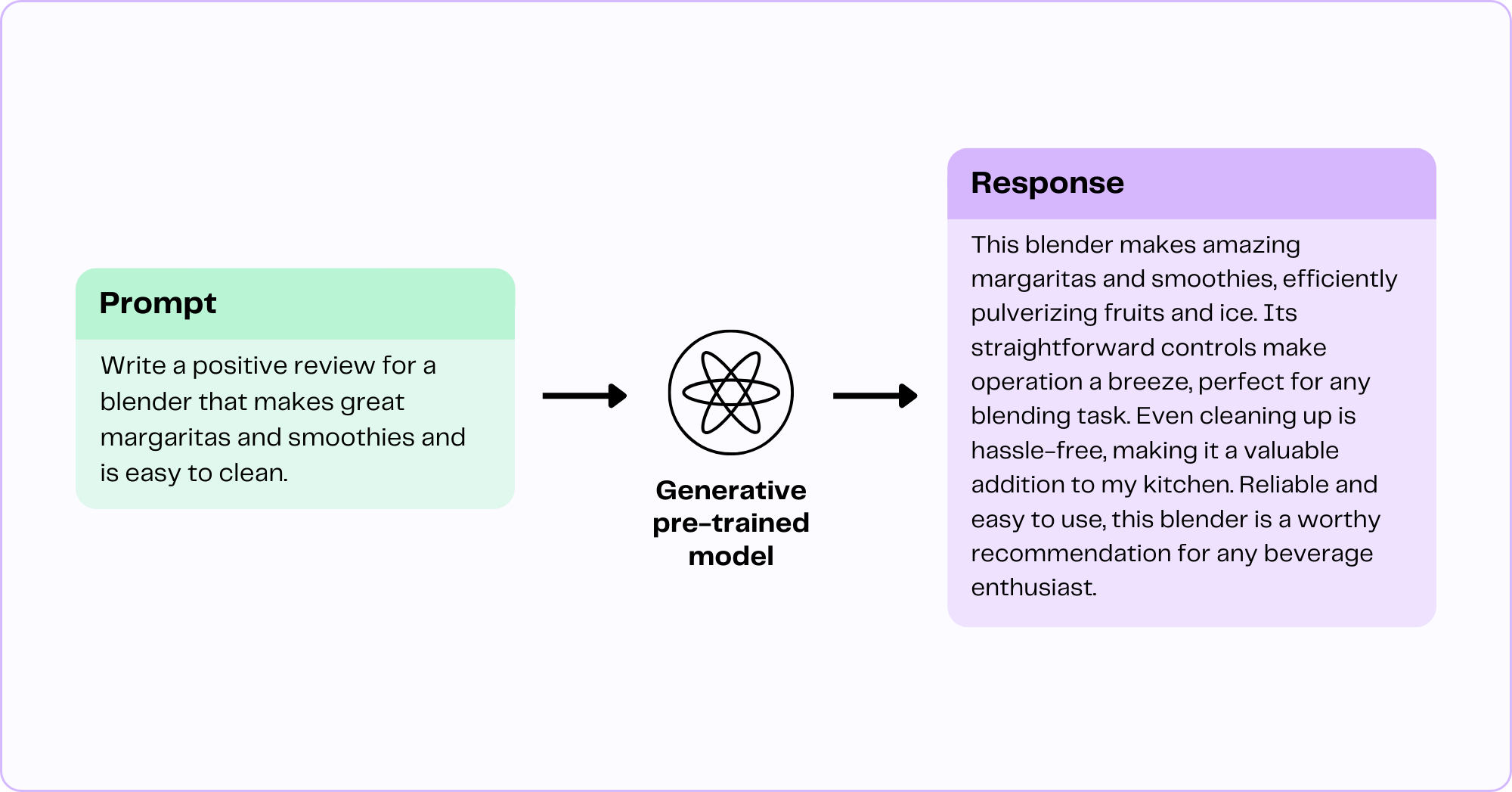
Although up for debate in the machine learning community, the easiest way to explain how a model generates new text is to say that it predicts the next word in a series based on the text the model was trained on and the text in the prompt. In the example below, the model predicts that the word "smoothies" has the highest probability of occurring next in the response. This is influenced by the fact that the model has learned from the training data that words like "smoothies" and "shakes" are related to "blender" as well as the fact that our prompt asks the model to mention the word "smoothies" in the response.
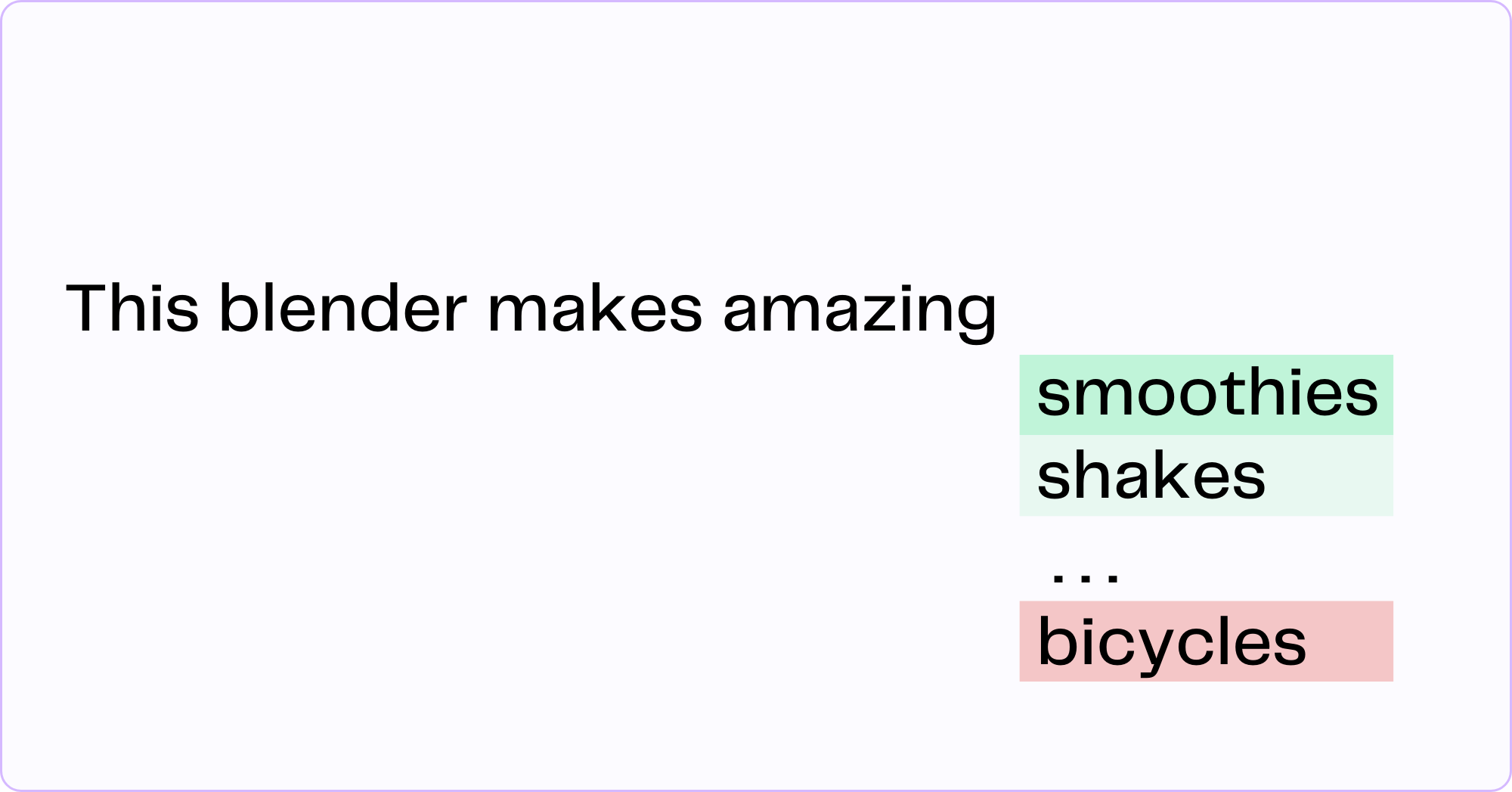
Given that "bicycles" are infrequently mentioned in the context of "blenders" in the training data and the fact that our prompt doesn't mention "bicycles," the model can safely assume that "bicycles" will not be the next word.
To summarize, generative machine learning models capture patterns, structure, and variations in the input data which allows them to calculate the joint probability of features occurring together. This enables them to predict probabilities of existing data belonging to a given class (e.g. positive or negative reviews) and generate new data that resembles the training data. But what exactly does this "new data" look like? The truth is, data generated by machine learning models can take many forms and serve a variety of purposes.
Like what you've read so far?
Become a subscriber and never miss out on free new content.
Generative AI in the real world
Generative models have been used in machine learning since its inception, to model and predict data. However, more recent advancements in the field, such as the emergence of variational autoencoder (VAE) and generative adversarial network (GAN) models in 2014, have propelled generative technology to new heights, enabling models to synthesize completely novel images. Likewise, the introduction of the first generative pre-trained transformer (GPT) model in 2017, marked a significant leap in language generation capabilities, leading to a succession of continuously improved language models capable of generating text indistinguishable from human-written text to the naked eye.
While major tech companies like Meta and Google have long invested in AI research and are constantly trying to one-up each other with each large language model they release, the startup world has also seen an explosion of interest in exploring the potential of AI, particularly generative models. Generative AI startups have collectively raised more than $17 billion in funding according to Dealroom, which maintains an excellent up-to-date visual landscape of funding in the field.
Let's take a look at how some of these companies are leveraging AI through products that generate text, images, and audio.
Generative text
Generative text refers to the use of AI models to generate coherent and contextually relevant sentences. These models, trained on vast amounts of text data, can mimic human-like language patterns and produce novel pieces of text. Real-world products include:
- AI chatbots: OpenAI's ChatGPT is the most capable personal assistant chatbot released to date. It can be used for a wide variety of tasks, including document summarization, text style transfer, language translation, and content generation. While it's a great general tool, many companies have further fine-tuned ChatGPT's underlying model to create products that are better at completing specific downstream tasks.
- Content generation: Jasper AI offers a customizable generative AI platform that caters to the specific needs of businesses, providing tailor-made content that aligns with a company's brand, and facilitating access across various platforms and applications, including the option to integrate its technology directly into businesses' products.
- Language correction: Grammarly provides a range of applications that offer integrated assistance for writing across many apps and websites, with a special emphasis on ensuring mistake-free writing. Their service is seamlessly integrated into a wide range of applications, like Microsoft Office, Google Docs, and Gmail through their handy plugins.
Generative images
Generative images involve the creation of new, original images by AI models, often by learning from a dataset of existing images. This fascinating intersection of art and technology has numerous applications, including:
- Artistic image generation: Adobe Firefly leverages the capabilities of traditional Adobe products, including Illustrator and Photoshop, with generative AI by allowing users to create, edit, and manipulate images through simple text prompts. Stability AI, offers a similar image editing and generation product called Clipdrop, which recently introduced the fascinating Uncrop tool, which uses generative AI to expand the background in photos.
- Presentation and visual storytelling: Tome empowers you to effortlessly craft captivating and contemporary presentations, seamlessly incorporating text and images from various sources such as prompts, creative briefs, or even different document formats like websites.
Generative audio
Generative sounds refer to the production of novel audio elements, including music, voice, and sound effects, using AI models. These models can learn from existing audio data and generate new, unique sounds. Here are some real-world use cases:
- Music production: Soundraw is an AI-powered music generator that offers a library of royalty-free tracks, allowing creators to produce original songs for their content projects while ensuring full ownership and licensing control over their music compositions.
- Voice synthesis: Wellsaid allows you to automatically generate high-quality voiceovers for text with access to a library of avatar voices and the opportunity to create your own.
Generative AI, significantly advanced through models such as variational autoencoder (VAE) and generative adversarial network (GAN), is reshaping multiple sectors with an investment of over $17 billion. Real-world applications span text generation, where AI can produce human-like language patterns, image creation, offering the ability to generate novel images, and audio production, where new sounds can be synthesized. These applications signify the expanding potential of generative AI in producing content increasingly similar in style and quality to human-generated content. And while recent advances in AI is certainly exciting, it's also important to acknowledge their inherent risks and limitations.
Risks and limitations of generative AI
Although fears that generative AI is just as dangerous, if not more dangerous than atomic weapons are sensationalized and overblown, this new technology presents real dangers to the general public and has serious ethical implications. Among some of the most critical concerns are issues related to data privacy, model accuracy and the tendency to produce harmful content, and unethical use of LLMs and other generative models.
Data privacy
One of the primary concerns surrounding generative AI is data privacy. These AI models are trained on vast quantities of data, some of which may include sensitive or copywritten information. Even though measures are often taken to anonymize and scrub data before training a model, the potential for inadvertent data leakage is a significant concern. Furthermore, generative AI nearly always needs a prompt to get started, and the information contained in that prompt could be sensitive or proprietary. This is concerning because some AI tools like ChatGPT, feed your own prompts back into the underlying language model. In April 2023, Samsung banned the use of ChatGPT within the company after it discovered that several employees had accidentally leaked source code for software that measures semiconductor equipment.
 Mark Gurman
Mark Gurman
Accuracy & harmful content
Another concern regarding the implementation of generative models is model accuracy. LLMs have the tendency to hallucinate, which means that they provide false information in a totally convincing manner. These hallucinations have the potential to disseminate misinformation on a global scale and can undermine public trust in AI systems. Because open source models generally undergo less stringent (if any) post-model alignment processes, they are especially at risk of "going off the rails," and going further than simply hallucinating; they produce downright harmful content. In March 2023, the National Eating Disorders Association shut down its human-operated telephone hotline and replaced it with a chatbot that ended up giving problematic weight loss advice to a psychologist independently testing the bot after it went live.
 By
By
Unethical use
As of the publication of this article, no significant legislation regulating the creation and application of AI has been passed. As a result, bad actors seem to have carte blanche when it comes to exploiting these tools for malicious intent.
The misuse of generative video technology swiftly became apparent when it was employed to harass and threaten women through the distribution of deepfake pornographic content. In March 2023, the Federal Trade Commission released a statement urging caution as phishing scams exploded in complexity thanks to the use of "voice cloning," an AI trained on a short audio clip of a person's voice that can then be prompted by text to say just about anything.

In summary, while generative AI is already doing amazing things and holds great promise, it's crucial to be aware of its risks and limitations, especially given the current lack of legislation regulating its creation and use. This means taking time to deliberately weigh the potential benefits of using generative AI with adverse consequences, taking ethical considerations into account. Here are some tips for safer, more mindful, and ethical use of generative AI products:
- Read (or at least skim) the privacy policies.
- Don't upload any private content (text, images, videos) that you wouldn't want to be fed back into the product's base model.
- If you're using a pre-trained generative model for business purposes, make sure to read the model's license.
- Verify responses from chatbots with primary sources.
- Research the specific biases and limitations of base models.
Conclusion
In this article, we've discussed the key aspects of generative machine learning models, particularly their capacity to differentiate between various data types and to create new data that closely resembles existing data. The quality of generative models has increased dramatically in the last decade, leading to an explosion of investment in the companies and technologies behind generative AI, namely in regard to generative text, images, and audio.
However, with this rise also come ethical concerns such as data privacy, model accuracy, and creating harmful content. We must continue to monitor these issues and practice personal vigilance and awareness when using generative AI products.
If you're interested in learning more about LLMs and other forms of generative AI -- then stay tuned for more great content on this topic by subscribing!
Sources
- Parrish, A. (2023, February 1). What’s the deal with this AI Seinfeld stream? The Verge.
- Williams, A. (2023, March 23). Paper written using ChatGPT demonstrates opportunities and challenges of AI in academia. Science Daily.
- Coscarelli, J. (2023, April 19). An A.I. Hit of Fake ‘Drake’ and ‘The Weeknd’ Rattles the Music World. The New York Times.
- IBM. (n.d.). What is artificial intelligence (AI)?. IBM.
- IBM. (n.d.). What is machine learning? IBM.
- Ngo, T. (2023, February 26). ChatGPT is NOT simply “predicting” the next word. LinkedIn.
- Kingma, D. P., & Welling, M. (2014). Auto-Encoding Variational Bayes. In International Conference on Learning Representations.
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). GAN(Generative Adversarial Nets. Journal of Japan Society for Fuzzy Theory and Intelligent Informatics, 29(5), 177.
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training. Preprint.
- Ullmer, F. & Chiavarini, L. (2023, June 9). Generative AI startups. Deal Room.
- Gurman, M. (2023, May 2). Samsung Bans Staff’s AI Use After Spotting ChatGPT Data Leak. Bloomberg.
- McCarthy, L. (2023, June 8). A Wellness Chatbot Is Offline After Its ‘Harmful’ Focus on Weight Loss. The New York Times.
- Latifi, F. (2023, June 7). Deepfake Porn Victims Are Seeking Federal Protections Through Legislation. Teen Vogue.
- Puig, A. (2023, March 20). Scammers use AI to enhance their family emergency schemes. Consumer Advice from FTC.
- Evans, K. (2023, May 10). AI best practices: How to securely use tools like ChatGPT. Infosec.
📝 A Non-Technical Introduction to Machine Learning (Safe Graph)
📝 Managing the risks of AI (Harvard Business Review)
👩🏫 Free generative AI course (Google)
💸 Generative AI startup funding map (Deal Book)